





When people think about AI infrastructure, they usually focus on large language model (LLM) training. But training is only the opening act. Ciena’s Francisco Sant’Anna explains that the real test—and the pressure on networks—is building quickly and at scale as AI inference evolves and LLMs move from AI factories into everyday products used by billions of people.
Massive GPU clusters in power-hungry data centers connected at petabit-scale for training offer a tangible and dramatic picture of AI’s impact on networks. Inference workloads, in contrast, are much lighter on a per-job basis. However, their growth is steeper, more global, and farther-reaching. As AI becomes more multimodal, more context-aware, and more deeply embedded across digital platforms, inference is emerging as a dominant driver of future network demand.
AI adoption is happening at an unprecedented pace
Technologies that have reshaped society—telephones, computers, the internet, smartphones—took decades to reach hundreds of millions of users. Even in the era of digital distribution, it still took years. Netflix needed ten years to reach 100 million users. Facebook took four. Instagram did it in just over two years. TikTok reached the milestone in nine months. However, AI accelerated this adoption timeline even further.
ChatGPT reached 100 million monthly active users (MAU) in just two months. Google’s Gemini app crossed 450 million MAU in less than 18 months. Beyond new AI apps, the bigger story is what happens when AI is embedded into existing digital platforms. Search, email, productivity software, maps, advertising, and social media already reach billions of users. Adding AI to them doesn’t create gradual adoption—it creates instant scale.
Google’s rollout of AI Overviews is a clear example. Within a year of introducing Gemini-powered capabilities into search, the feature was being used by more than 2 billion people every month. AI enhancements are now spreading across most of the product portfolios at Google, Microsoft, and Meta, as well as other leading digital platforms. The result is explosive growth in inference volumes. Google reported that the number of AI tokens (basic unit of text) it processes monthly increased 50x year over year in early 2025—and then doubled again just two months later.
AI inference volumes don’t translate directly into increased infrastructure demand, though. AI providers are improving inference efficiency to do more with existing resources. Microsoft, for example, reported delivering roughly 90% more tokens per GPU than the previous year. However, algorithmic and architectural efficiencies can only absorb a portion of inference workload growth. As AI usage scales across consumer and enterprise applications, massive volumes of GPUs—and rapidly expanding inference data centers—are being deployed globally. That compute growth and geographic distribution alone increase the importance of resilient, high-capacity connectivity between sites, even before considering how inference workloads themselves are evolving.
Text-based AI barely moves the needle—multimodal AI changes everything
So far, AI has had relatively minimal impact on overall internet traffic. Text-based interactions generate very little data—only a few kilobytes per exchange. Even at massive scale, that traffic is negligible compared to video streaming. Multimodal AI breaks this assumption.
Multimodal systems process and generate text, images, audio, video, and even 3D content. Besides typing prompts and receiving written responses, users can upload photos, stream video, or ask for rich visual outputs. A single high-definition smartphone video stream (720p at 30 fps) can require 2–3 Mb/s of sustained uplink bandwidth—roughly 15–22 MB of data per minute. Multiply that by hundreds of millions to billions of users, and inference traffic starts to look very different.
This shift is already underway. Google, OpenAI, Anthropic, xAI, Alibaba, and others now offer multimodal models. Usage of Google’s Search with Lens feature grew by billions of queries in just months. Product demos like Google’s Project Astra and OpenAI’s GPT-4o show real-time AI assistants processing live video feeds and responding contextually. Once these capabilities scale broadly, they will challenge long-standing assumptions about traffic growth in access, metro, and core networks – submarine and terrestrial.
Reasoning models and deep search add another layer of data movement
Inference workloads aren’t just getting bigger—they’re getting smarter and significantly more complex. Reasoning models break complex tasks into multiple internal steps before producing an answer. That hidden reasoning can require 3–10x more compute per query than traditional “instant” models.
These models also rely heavily on deep search. A single user query may trigger dozens of background retrievals—pulling in web pages, PDFs, images, or videos to support multi-step reasoning and research tasks. Even when users only see a short response, the network may be moving megabytes of data behind the scenes. Platforms currently set usage limits to contain the cost of these advanced capabilities, but demand is growing quickly. As they scale, they will materially increase inference-related data movement.
Bigger context windows mean more data in motion at inference time
Another quiet but powerful trend is the rapid expansion of model context windows. Context windows define how much information a model can process in a single inference session—conversation history, documents, instructions, and retrieved content. Over the past two years, frontier models have expanded context sizes at an extraordinary pace, roughly 30x per year.
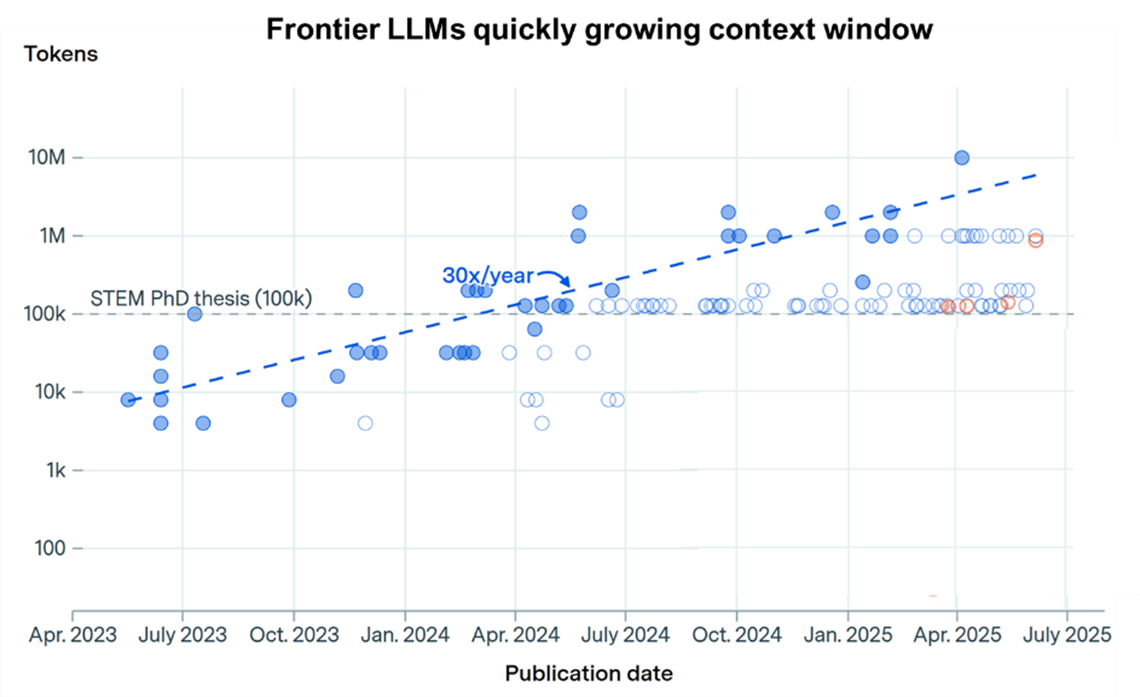
The size of the context window of frontier LLMs has been growing at an impressive rate of 30x/year
Source: Greg Burnham and Tom Adamczewski (2025), "LLMs now accept longer inputs, and the best models can use them more effectively". Published online at epoch.ai, Retrieved on 1/5/2026.
Larger context windows make techniques like retrieval-augmented generation (RAG) far more effective. Instead of training specialized models, RAG allows applications to inject large volumes of external data directly into prompts of generalist models to contextualize and enrich outputs and decisions at inference time.
This flexibility comes at a cost: increased upstream traffic from attaching supporting data into prompts, and additional downstream traffic from fetching RAG content from cloud-based sources prior to prompt injection.
What this means for AI networks
As inference scales, AI compute is becoming more geographically distributed. Models must be synchronized across regions. Usage data and learning signals must be shared. Complex inference workflows increasingly span multiple sites with complementary capabilities. All this drives substantial growth in DCI bandwidth, while also increasing the number of AI inference data centers to be connected.
Today, typical inference data center interconnect (DCI) links already operate at multiple terabits per second per route. Over the next five years, conservative assumptions from our analysis suggest these requirements could grow 3–6x, pushing per-route capacity into the tens—or even hundreds—of terabits per second.

Range of bandwidth requirement for AI inference data center interconnection, in (Tb/s)
Source: Ciena analysis
With so many interdependent and volatile variables influencing AI inference data flows, it’s difficult to forecast AI inference network impacts with precision. However, the direction is clear: inference is no longer a lightweight workload from a network perspective—it is becoming a primary driver of network design.
The bottom line
AI inference is moving from simple text queries to rich, multimodal, reasoning-driven interactions—at a global scale. That shift won’t just demand more compute, it will fundamentally alter data traffic patterns across access, metro, core (submarine and terrestrial), and data center networks.
For network operators, AI inference-driven demand is no longer a secondary consideration. It is becoming one of the defining forces shaping how AI-ready networks are designed—driving changes in data center distribution and creating significant connectivity opportunities across wholesale and enterprise segments.
As AI inference reshapes traffic patterns, Ciena’s focus on scalable, high-capacity, and resilient architectures positions it to support operators through the next phase of AI-driven network evolution.