





March 25, 2026
By Brian McDonald
Americas CTO Office, Ciena
AI infrastructure is entering a new phase. As agentic AI demands more orchestration, memory handling, and tool execution from CPUs, networks must evolve from passive interconnects into programmable, high-capacity infrastructure that can support distributed AI workflows. Ciena’s Brian McDonald details below.
For the better part of a decade, the AI infrastructure growth narrative was single-faceted: more GPUs, faster GPUs, bigger GPU clusters. Service providers built and scaled the networks that connected them, and for the era of large-scale model training, that was the right infrastructure contract. But a quiet architectural shift is happening, one driven by the renaissance of CPUs, not the next generation of accelerators. That renaissance signals something important: AI is expanding beyond centralized, training-dominated workloads into distributed, orchestration-heavy ones — and the network is no longer just connecting the compute infrastructure. It is becoming part of it.
The 2026 inflection point: beyond the "GPU-only" narrative
Cast your mind back to as recent as 2024. As the industry evolved to support both a persistent pre-training gold rush and a new era of increasing-scale inference, AI infrastructure underwent a topology slimming. While training clusters once required a dense 4:1 ratio to handle heavy data-loading, the focus shifted toward eliminating the 'CPU tax' that plagued high-scale inferencing. In custom inference-optimized deployments like Google’s TPU v6e and Meta’s Grand Teton, the GPU-to-CPU socket ratio moved to 8:1.
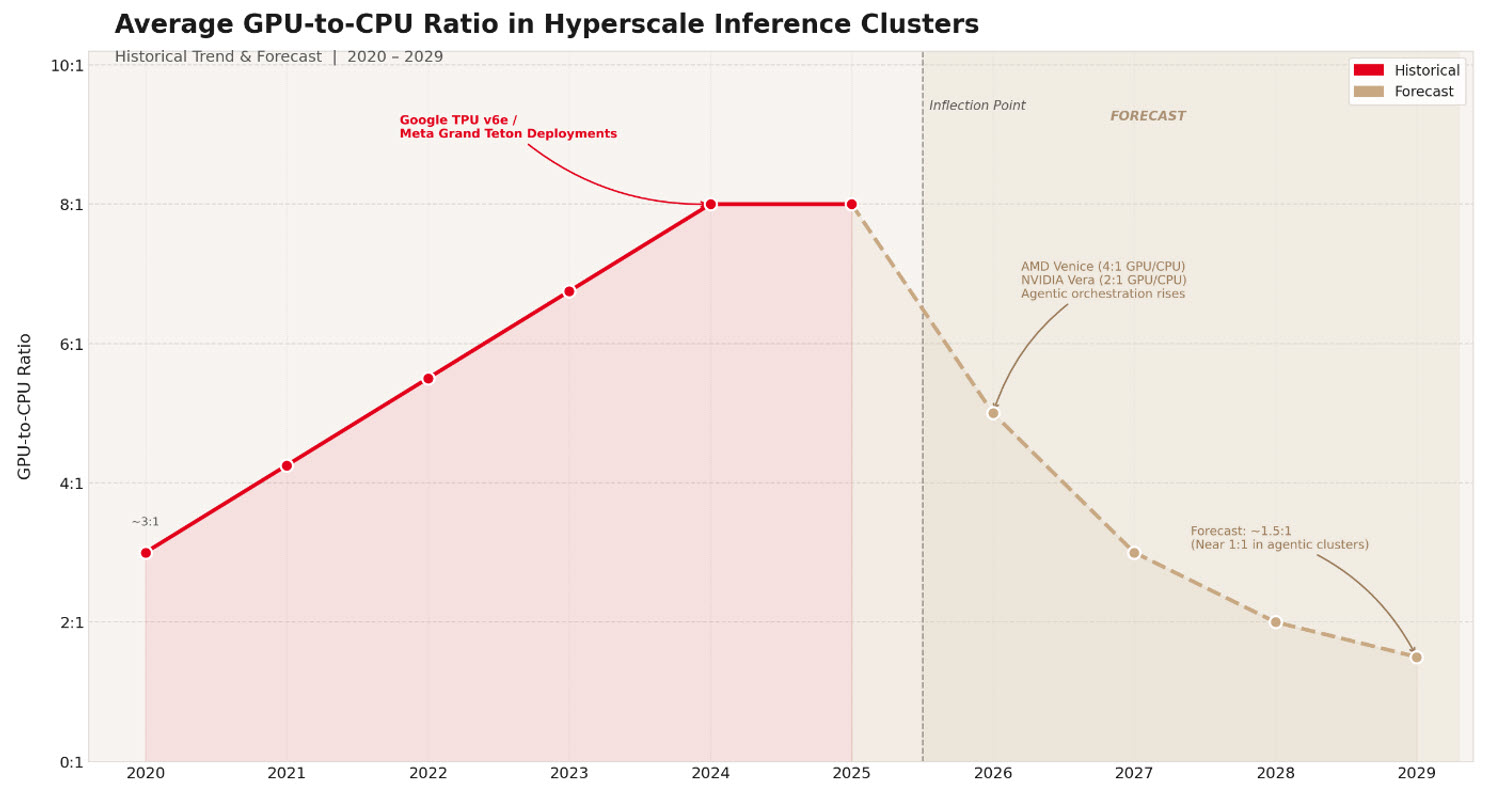
Trend derived from Ciena analysis of published cluster specifications from Google, Meta, NVIDIA, and AMD.
Today, forward-looking cluster designs are reintegrating high-core-count CPUs to a leading role in the compute hierarchy, with some expecting GPU-to-CPU ratios narrowing to 1:1 in certain clusters. That’s the case of clusters specifically designed to handle reinforcement learning environments, tool invocation, logic gating, and document merging. Specific 2026-era hardware pairings illustrate this narrowing gap:
- AMD Venice: 1 CPU to 4 MI455X GPUs per compute tray.
- NVIDIA Vera: 1 CPU to 2 Rubin GPUs per superchip.
- Google TPU7x: 1 CPU to 4 TPU chips per scale-up unit.
Agentic AI: the forcing function
The shift from user-initiated generative AI to agentic AI is the single most consequential driver of this hardware rebalancing. Generative AI responds to prompts. Agentic AI pursues goals. It plans, executes multi-step tasks, interacts with tools and external environments, and adapts continuously.
This distinction has profound infrastructure consequences. A traditional LLM inference call is a relatively self-contained GPU event. An agentic workflow can be seen as analogous to an operating system: spawning threads, managing memory, calling tools, engaging through APIs, and iterating through reinforcement loops.
Consider the token economics alone: a single inference request of 50 tokens of text can evolve into a 50,000-token job as it fans out across agents. That 1,000x expansion represents more than just GPU compute, it means more of the orchestration logic and tooling that run on CPUs.
The WAN propagation: from data center to wide area network
This compute transformation doesn't stay contained within the data center (DC) walls, it propagates directly into the wide area network (WAN), and the implications are substantial.
AI infrastructure is shifting from centralized execution to distributed workflows spanning multiple systems, domains, and data sources. As agentic workloads scale, they inevitably span multiple data centers, colocation facilities, and cloud regions, creating a new class of traffic: constant, bursty, and bidirectional.
Disaggregated execution is the core mechanism. When an agent's workflow is broken into granular, hardware-optimized steps — GPU nodes for inference, CPU nodes for orchestration — state and memory must be shared constantly across the cluster and beyond. The Key-Value (KV) cache, which stores the entire interaction history of a multi-turn agentic loop, must be reloaded, offloaded, and shared across nodes as execution hops between hardware tiers. At 32K token context lengths, the bandwidth math points to 200–400 Gbps link capacity as a practical floor for KV cache transfers that meet inference SLA requirements.
Even so, KV cache demands are not static. They scale with model size, grow linearly with context length, and in agentic workflows, never reset. They accumulate continuously across multi-step reasoning chains. What may be a 10 GB cache for a single inference quickly becomes a moving bandwidth floor that compounds with every agent interaction.
This is no longer theoretical. AI traffic entering downstream networks is high‑bandwidth, spiky, and always‑on by design. The WAN, built for an era of download-heavy, human-initiated traffic, was not architected for the symmetric, machine-generated, latency-intolerant flows that agentic AI produces.
The networking imperative
Three network architectural responses have become critical to support the AI infrastructure revolution.
- Rethinking the fabric within clusters (scale-up & scale-out): traditional Ethernet is insufficient for the latency-sensitive, bandwidth-intensive nature of AI training. Model builders rapidly transitioned to RDMA over Converged Ethernet (RoCE) and InfiniBand to support lossless, high-throughput connectivity between heterogeneous compute nodes.
- Connecting clusters (scale-across): extends lossless connectivity between data center campuses or regions to support distributed AI model operations. This demands dedicated coherent optical transport with substantially more total capacity than standard deployments. This new "AI WAN" is not an incremental upgrade to existing infrastructure; it is a purpose-built layer for AI-native traffic flows.
- Architecting for agents: dynamic integration of resources and platforms must bridge the software-hardware divide. As CPU-heavy orchestration layers and GPU-heavy inference layers operate in tandem across distributed infrastructure, intelligent schedulers, load balancers, and compilers must route workloads to the right hardware in real time — continuously monitoring cost models, cache locality, and model availability.
We have already seen the magnitude of change the first response had (and continues to have) on cluster architectures. As we experience the impact of the second, it allows us to imagine the implications of the third.
What does this mean for networks?
This high bandwidth, spiky, always-on, symmetrical traffic from inside the DC, will spill out into the WAN as agentic AI becomes more synonymous with distributed AI. This means that:
- Super‑linear traffic growth between compute regions mandates next‑generation Data Center Interconnect (DCI)
- Agentic workloads demand fabric‑like dynamic connectivity as static hub‑and‑spoke networks hit scaling ceilings
- Network automation becomes mandatory as workload complexity increases
The bottom line
The era of the homogeneous GPU cluster is drawing to a close. Agentic AI demands a new infrastructure contract. One where CPUs are repatriated into cluster architecture as essential orchestration engines, where the GPU-CPU ratio reflects the true complexity of multi-step AI workflows, and where the network is treated as a first-order performance determinant. For service providers and enterprises, this shift is decisive: those who evolve their networks into programmable, high‑capacity substrates for distributed AI will become critical enablers and winners of the agentic era, while those who don’t, risk watching AI — and its traffic — bypass their networks and business.