As AI training scales beyond the limits of a single data center, a new architectural model is emerging: scale across. In this blog, Brodie Gage explores how distributed AI training is reshaping optical infrastructure—and details how Ciena is advancing the coherent and photonic innovations powering regional and multi-regional scale across applications.
AI and cloud applications are rewriting the rules of infrastructure, as I talked about before. This is changing not only how AI models are trained, but also how the networks supporting them must be built.
You’re seeing this firsthand. As models become more complex and data sets become larger, AI training environments are scaling at an unprecedented pace. Only recently, state-of-the-art clusters were measured in the tens of thousands of GPUs. Today, clusters are scaling into the hundreds of thousands of GPUs, with the industry rapidly approaching the era of million-plus GPU training environments.
That kind of growth is forcing a fundamental shift in network architecture.
Power density constraints alone are pushing AI infrastructure beyond the four walls of a single data center. Instead of a training model in one facility, customers are increasingly distributing clusters across multiple sites, campuses, and, increasingly, regions.
At Ciena, this shift is directly influencing how we evolve our coherent optics, pluggables, and photonic systems. We’re not simply increasing capacity; we’re re-architecting the optical foundation to support distributed AI at unprecedented scale. These advancements, which I’ll describe later, started with a critical question:
How do you maintain a single, synchronized AI training environment when the infrastructure is physically dispersed?
This is where a new architectural paradigm is emerging: Scale Across.
What is scale across?
Much of the AI infrastructure conversation has focused on scale up or scale out. Now, we’re seeing rapid adoption of scale across architectures.
Scale across extends AI training beyond a single data center—enabling one AI model to be trained across GPUs located in different campuses or even regions. In other words, it’s the ability to build one logical AI training environment, even when the infrastructure is physically distributed.

Scale across: Extending lossless connectivity between datacenter campuses or regions to support the training of a single AI model
And making that possible isn’t simply about adding bandwidth.
AI training workloads are highly sensitive to network behavior. Packet loss, congestion, and inconsistent latency can slow training dramatically—and the impact compounds as distance increases.
Scale across introduces new requirements at multiple layers of the network:
- Smarter traffic and congestion management in the packet layer
- And critically, a new foundation of optical connectivity underneath
Once training extends beyond a campus, traditional interconnect approaches are no longer enough. For the first time, coherent optical technology is becoming an essential enabler of distributed AI training architectures.
We’re hearing this challenge consistently in our conversations with cloud and AI infrastructure leaders. As the industry leader in coherent optics and photonic line systems, Ciena is collaborating closely with customers to develop new architectures and tailored solutions that make scale across possible.


For the first time, coherent optical technology is becoming an essential enabler of distributed AI training architectures.
Coherent optics becomes foundational to the AI cluster
Connecting AI clusters across distance requires a very different class of optical network than traditional metro DCI.
You’re not simply adding bandwidth between two sites. You’re extending a tightly synchronized AI training environment over distance—where capacity, reliability, and latency directly impact model performance.
That means the optical layer must deliver:
- Ultra-high capacity
- Extremely high reliability
- Consistently low and predictable latency
And it must do so at a scale well beyond conventional data center interconnect deployments. This is where coherent optic and photonic layer innovations become foundational—not just to connectivity, but to AI performance itself.
Two scale across architectures emerging: near and far
In our conversations with customers, we’re seeing two primary architectural directions emerge, each with distinct requirements.
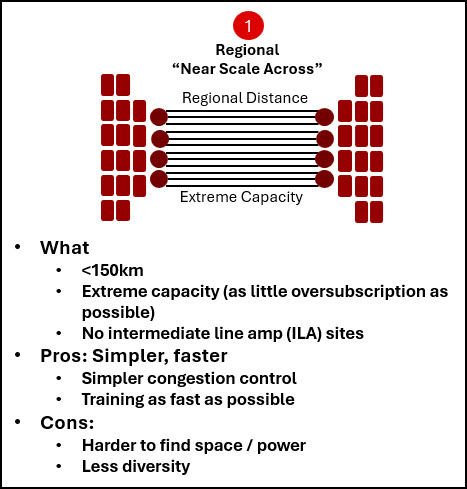 Near scale across: purpose-built for regional connectivity
Near scale across: purpose-built for regional connectivity
Near scale across focuses on extending AI training across a metro or regional footprint while keeping latency low and the architecture as simple as possible. The trade-off is clear: space and power remain scarce, and resiliency options may be more limited.
When we began developing a new line system for this application, the directive from customers was unmistakable: maximize reach while avoiding intermediate line amplifier sites “at all costs.” And we needed to define, develop, build, ship, and deploy the solution in less than a year.
To meet this challenge, our team at Ciena leveraged our unique industry experience and worked closely with customers to deliver a purpose-built photonic line system optimized specifically for single-span scale across connectivity.
A key innovation we are delivering is the use of both C- and L-band coherent technology in this passive, point-to-point context, effectively doubling the number of high-capacity connections over the same fiber infrastructure. This is critical as AI clusters demand unprecedented bandwidth—while space and power remain at a premium. Supporting this level of scale introduces new requirements for both coherent pluggables and photonic line systems.

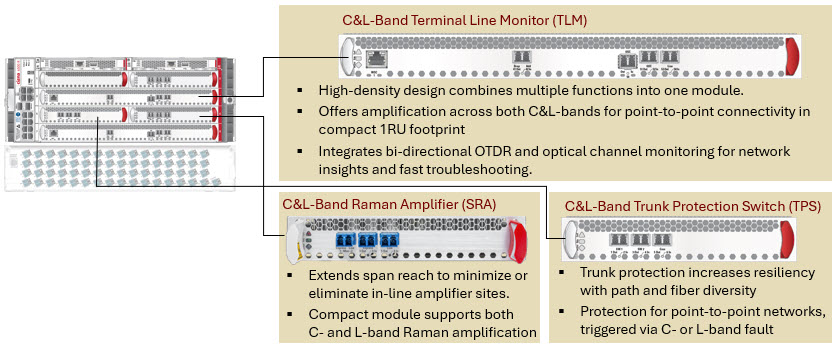
Ciena optimized “near scale across” configuration
With respect to pluggables, our WaveLogic 6 Nano 800Gb/s coherent pluggables are now available in L-band in addition to C-band, enabling expanded spectrum utilization for these deployments. This is particularly important, as customers require an exponential increase in traffic between sites—tens of Pb/s—deploying tens of thousands of connections in compressed timeframes and are often unable to activate networks until full capacity is in place. At the same time, these pluggables deliver industry-leading performance while supporting interoperable 800G ZR+, ensuring customers can meet both capacity and openness requirements as they scale.
At the foundation of these deployments is Ciena’s new RLS C&L-band line system configuration (additional details below), co-developed directly with hyperscalers to address the unique demands of near scale across architectures. The compact C+L solution fits within just 6RU for an optically protected terminal and incorporates new power modules that enable seamless deployment directly into standard data center racks.
To further extend single-span reach, the system leverages Raman amplification to support stretched-span performance—reducing the need for intermediate amplification sites, which can introduce major practical challenges around facilities, real estate, and power.
And because AI training environments demand extreme resilience, the solution includes an integrated optical protection switching capability, ensuring ultra-high reliability by rapidly responding to failures across either the C- or L-band spectrum.
Together, these innovations provide the optical foundation needed to scale AI infrastructure across campuses with the capacity, simplicity, and reliability that near scale across demands.
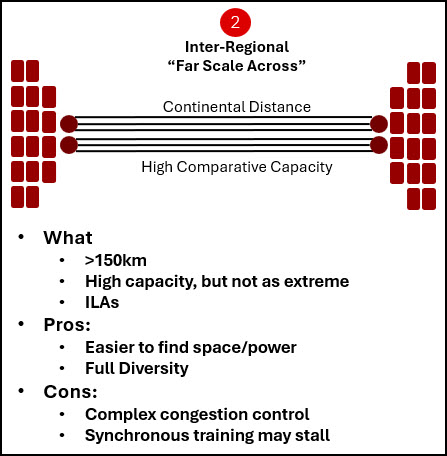 Far scale across: reinventing photonics for multi-region AI
Far scale across: reinventing photonics for multi-region AI
For many of you, far scale across is attractive because it opens up far greater flexibility—access to more space and power, broader geographic distribution, and stronger options for disaster recovery and resiliency.
But it also introduces a very different set of space and power constraints along the route.
At multi-region distances, intermediate line amplifier (ILA) sites are unavoidable. Traditional photonic line system designs were never built for the scale required by these architectures. Supporting an order of magnitude more traffic, across hundreds of fiber pairs, while maintaining tight space and power efficiency demanded a fundamentally new approach.
In short, we had to rethink the line system architecture.
Working closely with hyperscalers and service providers, we developed new intermediate line amplifier configurations capable of supporting dramatically higher fiber counts and traffic volumes—while still fitting within the same operational footprint. Where traditional line amplifier systems support a single fiber pair per chassis, far scale across requirements demanded significantly higher density.
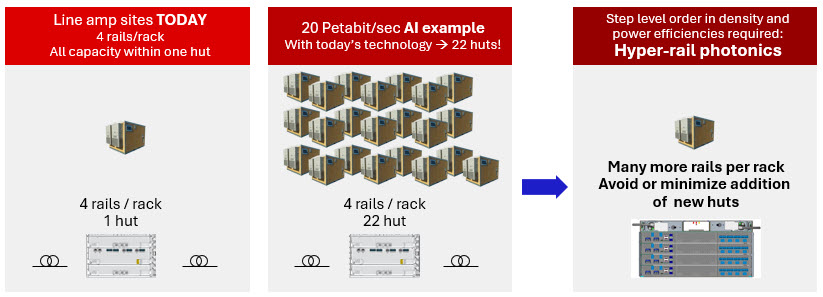 Massive densification of amplifier sites required to support new distributed AI training requirements
Massive densification of amplifier sites required to support new distributed AI training requirements
The result is our new RLS Hyper-Rail configuration. Designed specifically for large-scale, multi-region AI connectivity, it delivers an order-of-magnitude increase in fiber density—while fitting seamlessly within existing rack footprints.
This level of density is critical. By dramatically increasing fiber capacity per rack, customers can significantly reduce—or even avoid—the need for additional amplifier huts at each site, lowering space and power demands as well as the complexity of securing and developing new real estate.
Far scale across pushes optical infrastructure into new territory. With RLS Hyper-Rail, we’re giving customers the scalable, high-density photonic foundation needed to connect AI clusters across regions—efficiently and sustainably.
Building the first tailored optical systems for scale across
Scale across is more than a networking evolution—it’s a new architectural model for AI infrastructure.
As distributed training becomes the norm, the optical network moves from a supporting role to a strategic enabler. This is where the fun starts for us at Ciena, getting in the lab and working alongside customers to develop the coherent and photonic layer innovations that make this possible. Helping operators like you scale AI infrastructure across campuses and regions with performance, efficiency, and confidence.
And just as importantly, we understand that success in this new era isn’t only about ultimate scale—it’s about speed to scale. As AI environments grow exponentially and deployment timelines compress, customers need optical solutions that can be designed, delivered, and turned up rapidly, without compromising reliability or openness.
We’re excited to help shape this next chapter of AI infrastructure together.
More details on Ciena’s RLS “near scale across” configuration